Advanced Analytics and Machine Learning (AAML)
Prof. Dr. D. Kranzlmüller
Dr. Andre Luckow
Dr. Karl Fuerlinger
News
- 16.05.2022: The room for the oral exam is: Besprechungsraum EU102
- 13.05.2022: The schedule for the oral examination is available now. The exam will take place in person at Oettingenstr. Room will be announced early next week.
- 10.05.2022: The oral examination is confirmed for May 20, 2022 and will take place between 12pm and 6pm.
- 10.04.2022: The oral examination is scheduled to take place on May 20, 2022 (tentative).
- 08.04.2022: Project recommendations available here.
- 02.04.2022: Example for project choice submission available in downloads
- 01.04.2022: New Location: Hörsaal B U101
- 27.03.2022: The application period for AAML has be closed. To finally secure your seat, please be on time for the lecture on April 2, 9 am, ct (in-person at LMU, Oettingenstr.). Seats not claimed will be given to standby participants.
- 20.03.2022: The first block lecture will take place on April 2, 9 am c.t., in room 061 (presence required to attend course). Please, be aware that we will enforce the 3-G rule. Please, bring your certificate to the LMU. Further, a mask must be worn during the event.
- 26.02.2022: Dates: The lecture will take place between April 2 and April 14, 2022.
Content
The ongoing data deluge driven by the increasing digitalization of science, society and industry, leads to a significant increase in demand for data storage, processing and analytics within several industrial domains. Sciences and industry are overwhelmed by the need to store large amounts of transactional and machine-generated data resulting from the customer, service and manufacturing processes. Examples of machine-generated data are server logs as well as sensor data that is generated in finer granularities and frequencies. Further, datasets are often enriched with web and open data from social media, blogs or other open data sources. The Internet of Things (IoT) will further blur the boundaries between the physical and the digital world causing an even further increase in the digital footprint of the world. In this course, we will learn about data applications and their requirements. In this lecture, we will learn about methods and technologies for handle the large data volumes, analytics and machine learning. As part of the exercises students will utilize different frameworks, e.g., MapReduce, Spark and Tensorflow/Keras, to implement different algorithms.
This class will cover the following topics:- Data applications in industry and sciences
- Data-intensive methods in high performance computing
- Large-scale data processing using Spark, Dask, Flink and Ray
- SQL for unstructured data: Hive, Spark-SQL, Presto
- Stream processing: Kafka, Spark Streaming, Flink, Heron
- Data science and machine learning: unsupervised and supervised methods, tools (numpy, pandas, scikit-learn)
- Deep learning: convolutional neural networks (Tensorflow, Keras)
- Natural language processing: word embeddings, large language models (RNNs, LSTMs, Transformers)
- Quantum machine learning (New 2022!)
- AI Ethics
Audience
The lecture is aimed at master's and bachelor's degree students in the computer science and data science programs.
Exercises
Exercises and code for the exercise are under: https://github.com/scalable-infrastructure/exercise-students-2022 verfügbar.Scope and Exam
The class comprises 14 modules and 10 exercises (6 ECTS).
The final grade of the class is determined based on a project work and an oral examination. In order to be admitted, all exercise must be submitted and passed. For the lecture to be successful, a grade of at least 4 must be achieved.
Pre-Requisites
Attendance of the lectures on computer networks and distributed systems, operating systems, computer architecture or comparable knowledge required. Programming knowledge in Python and handling Linux command line required.Time and Location
Time / Dates : April 2 to 14, 2022.
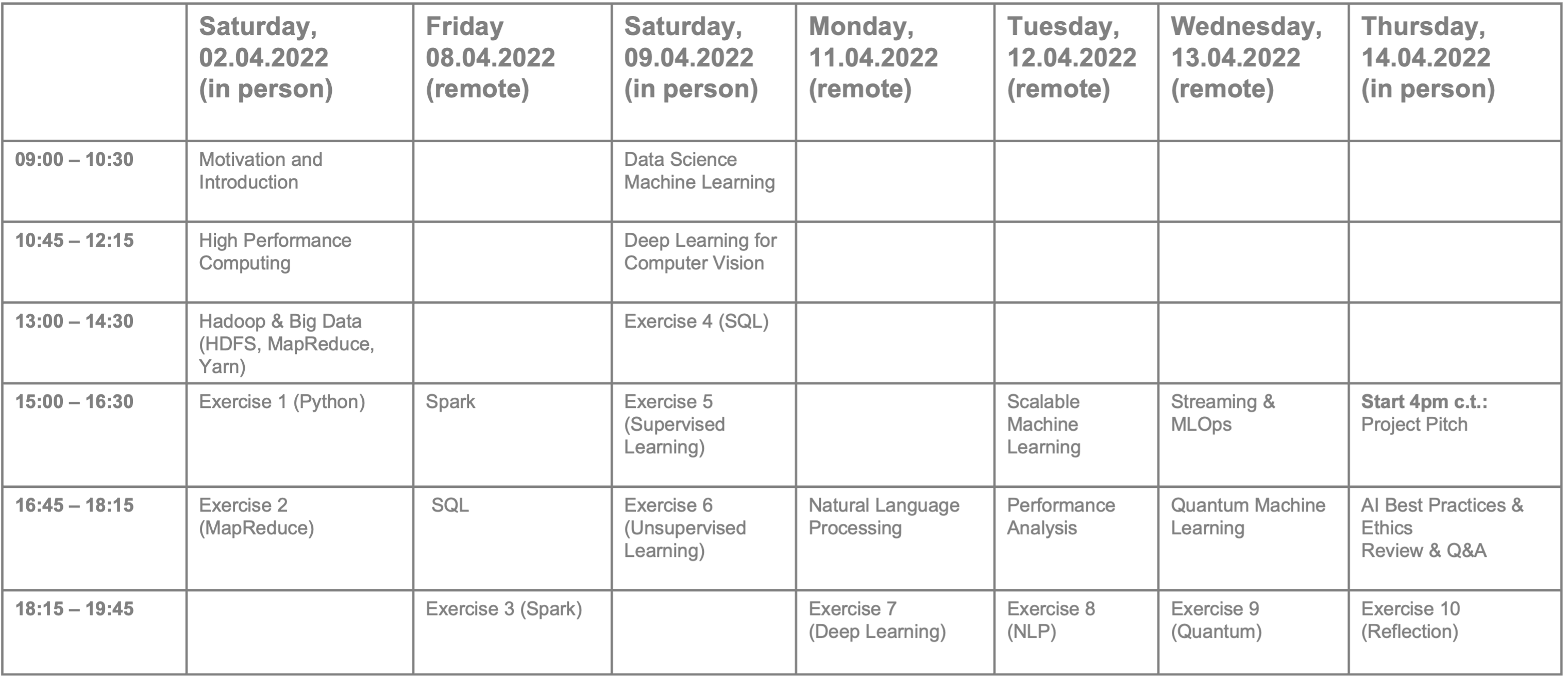
Tentative Schedule:
Location (Hybrid):
- LMU, Oettingenstr. 67,
Room 61Hörsaal B U101 (NEW Location! ) - Zoom (Passcode will be send to participants)
Enrollment: The places will be allocated via UniWorX: Uni2Work-Application.
We ask you to describe your previous knowledge in your application and to motivate your participation.
Downloads
Introduction, HPC, Hadoop and Spark
Project Choices Example
Data Science, Machine Learning, Deep Learning, NLP, MLOps
Recording Scalable ML and Benchmarks
Quantum Computing and AI Best Practices
Contact
For questions or inquiries please contact Andre Luckow.