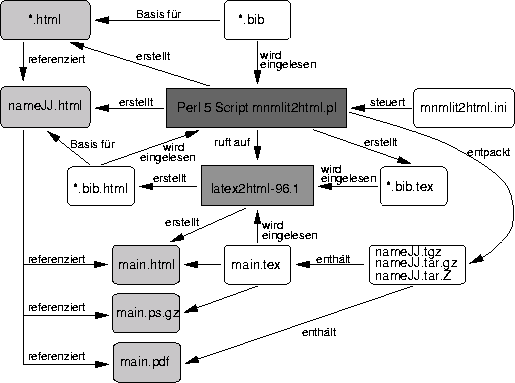
Nach dem Auslesen einiger Pfadkonstanten wird zunächst die
Konfigurationsdatei eingelesen. Daraufhin entpackt das Script
den Sourcecode eines oder mehrerer Dokumente, die in einem
definierten Verzeichnis abgelegt wurden. Das Programm sucht
nach Dateien mit den Endungen .tgz, .tar.gz und
.tar.Z und entpackt diese in einem temporären Verzeichnis.
Alsdann durchsucht es das angegebene Verzeichnis, in dem sich die
BibTeX-Dateien befinden, scannt die gefundenen Dateien nach den
in der Initialisierungsdatei .mnmlit2html.ini spezifizierten
Einträgen und speichert diese in einem Hash. Der Hash ordnet den
Schlüsseln der BibTeX-Datei (allg97, kene97, ...) die einzelnen Felder
(author, title, key, ...) zu. Dazu war es nötig, den assoziativen
Array, wie der Hash unter Perl auch genannt wird, zu verschachteln.
Die dem Schlüssel zugeordnete Information bestand ihrerseits wieder
aus einem assoziativen Array.
Da die Informationen, die der Hash speichert, öfters benötigt werden,
bot sich diese Methode besonders an, da auf einen Hash
schneller zugegriffen werden kann als auf ein einfaches Array oder
mehrere Stringvariablen.
Im folgenden Schritt werden pro entpackter Datei die dazugehörigen
Vorabtitelseiten erstellt. Hierzu werden die Dateien mittels des
Hilfsprogramms LaTeX2HTML nach HTML konvertiert und anschließend
nach Schlüsselwörtern durchsucht, anhand derer eine Zusammenfassung
des vorliegenden Dokuments erzeugt wird. Schlüsselwörter
sind etwa Zusammenfassung, Einführung, Abstract o.ä.
Die Schlüsselwörter
können in der Konfigurationsdatei angegeben werden. Zusammen mit
den im Hash erfaßten Daten über Autor, Titel, Erscheinungsjahr und
-monat erscheint die Zusammenfassung auf der Vorabtitelseite. Diese
ist in HTML abgefaßt und kann in Abbildung1.3 auf Seite
![]() beispielhaft betrachtet werden.
beispielhaft betrachtet werden.
Im darauffolgenden Schritt werden die generierten HTML-Seiten
sowie die zum Dokumentationsbaum gehörige Postscript-
sowie PDF-Datei an ihren entgültigen Bestimmungsort kopiert.
Falls die Postscript-Datei unkomprimiert vorliegt, wird
sie mit GNU-Zip komprimiert, um Plattenplatz und Bandbreite
bei der Übertragung zu sparen. Zusätzlich gibt eine in Klammern
angefügte Zahl die Größe der komprimierten Datei in Kilobyte an,
damit jeder für sich entscheiden kann, ob es sich lohnt die Datei
herunterzuladen. PDF-Dateien sind von Haus aus schon recht
kompakt, so daß auf eine derartige Behandlung verzichtet wurde.
Um auf die einzelnen Arbeiten gezielt zugreifen zu können,
wird am Schluß noch eine thematische Inhaltsübersicht
erstellt, die in Abbildung1.2 auf Seite
![]() betrachtet werden kann.
Im vorliegenden Fall stimmen diese Inhaltsübersichten
mit den Namen der einzelnen BibTeX-Dateien überein. Die
Inhaltsübersicht enthält eine Auflistung sämtlicher gefundener
Dokumententitel, deren Autor, Jahr und Monat sowie sämtlicher
Einträge, die in der Konfigurationsdatei als ,,
zu Veröffentlichen``
gekennzeichnet sind. Ausgehend vom Titel des jeweiligen Dokuments
kann per Hyperlink die Vorabtitelseite des Dokuments erreicht
werden, sofern der Quellbaum des Dokuments schon übersetzt wurde.
betrachtet werden kann.
Im vorliegenden Fall stimmen diese Inhaltsübersichten
mit den Namen der einzelnen BibTeX-Dateien überein. Die
Inhaltsübersicht enthält eine Auflistung sämtlicher gefundener
Dokumententitel, deren Autor, Jahr und Monat sowie sämtlicher
Einträge, die in der Konfigurationsdatei als ,,
zu Veröffentlichen``
gekennzeichnet sind. Ausgehend vom Titel des jeweiligen Dokuments
kann per Hyperlink die Vorabtitelseite des Dokuments erreicht
werden, sofern der Quellbaum des Dokuments schon übersetzt wurde.
Nach einem Hinweis über den Erfolg der übersetzten Seiten
ist das Programm beendet. Die Beziehungen der einzelnen Skripten
zueinander und zur Umgebung stellt die
Abbildung2.1 auf Seite
![]() dar.
dar.