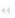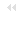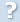 |
|
| ||||||
| |||||||
TCP/IP und das Internet | |||||||
Das Internet ist eine lose Verbindung vieler einzelner Rechnernetze unterschiedlichster Architekturen. Ein solche Verbindung von Rechnernetzen setzt eine gemeinsame Basis zur Kommunikation zwischen den Netzen voraus. Hierfür wird die Internet-Protokoll-Familie eingesetzt. Der Name dieser Protokoll-Familie setzt sich aus den Abkürzungen für die beiden wichtigsten Protokolle, Transport-Control-Protokoll (TCP) und Internet-Protokoll (IP), zusammen. Der Einsatz dieser Protokoll-Familie ermöglicht es, Netze, die auf den Schichten 1 )(Bitübertragungsschicht) und 2 (Sicherungsschicht) des OSI Schichtenmodells vollkommen unterschiedliche Protokolle verwenden (z.B. Ethernet, Token Ring, ATM, ...), durch den Einsatz des Internet Protokolls (IP) auf der Vermittlungsschicht zu verbinden. Neben IP und dem von vielen Anwendungen verwendeten verbindungsorientierten TCP (Transport Control Protocol) auf Schicht 4 gibt es noch eine Vielzahl anderer Protokolle, z.B. UDP und ICMP, die zur Internet-Protokoll-Familie zählen. Wenn im folgenden von TCP/IP gesprochen wird, so bezieht sich dies immer auf die gesamte Internet-Protokoll-Familie und nicht nur auf die beiden Protokolle IP und TCP. | |||||||
Die TCP/IP-Protokollarchitektur | |||||||
Die Kommunikation in einem TCP/IP Netz, und somit auch im Internet, wird gemäß den Schichten des OSI-Referenzmodells (siehe Abbildung 1.1) betrachtet. | |||||||
| |||||||
Auf der Vermittlungsschicht (Schicht 3 des OSI Referenzmodells) wird das Internet-Protokoll (IP) eingesetzt. Dieses Protokoll sorgt mittels Nachrichtenvermittlung für die Beförderung einzelner Datagramme (IP-Pakete) von einem Quellrechner bis zu einem Zielrechner. Die Dienste des Internet Protokolls nutzend, gibt es auf der Transportschicht (OSI Schicht 4) im wesentlichen zwei Protokolle, die für die Kommunikation zwischen den Anwendungen auf Quell- und Zielrechner verwendet werden. | |||||||
Das Transport Control Protocol (TCP) bietet der Anwendung eine sichere virtuelle Verbindung. Das Protokoll sorgt für die Reihenfolgesicherung, eliminiert Duplikate und stellt sicher, dass alle Pakete intakt zum Ziel gelangen. Im Gegensatz dazu bietet das User Datagram Protocol (UDP) eine verbindungslose Kommunikation an. Diese Kommunikation ist unsicher, da das Protokoll keine Möglichkeit bietet zu überprüfen, ob ein Datenpaket das Ziel korrekt, in der richtigen Reihenfolge und nur ein einziges mal erreicht hat. Für viele Anwendungen ist dies aber auch nicht notwendig. Aufgrund des Geschwindigkeitsvorteils den UDP im Gegensatz zu TCP bietet, ist UDP daher oft das bevorzugte Protokoll. | |||||||
Die Schichten 5 und 6 des OSI Referenzmodells sind in der Internet-Protokoll-Familie nicht implementiert. Alle Protokolle der Anwendungsschicht nutzen direkt die Dienste der Protokolle auf der Transportschicht. Beispiele für Protokolle der Anwendungsschicht, die Dienste der Internet-Protokoll-Familie nutzen, sind HTTP, FTP, Telnet, SMTP, SNMP, DNS, BOOTP und DHCP. | |||||||
Adressierung und Wegewahl in IP-Netzen | |||||||
Doch wie findet ein Paket den Weg zur richtigen Anwendung auf dem richtigen Rechner? Für die Zustellung eines Pakets sind im wesentlichen drei Schritte notwendig: | |||||||
| |||||||
ADRESSIERUNG | |||||||
Alle Rechner, die IP verwenden, werden durch eindeutige 32-bit Adressen (sog. Internetadressen) identifiziert. Die 4 Byte dieser IP-Adresse werden meist als durch Punkte getrennte Dezimalzahlen geschrieben (z.B. 192.168.215.81). | |||||||
Eine IP-Adresse besteht aus zwei Teilen, einem Netzteil und einem Hostteil. Der erste Teil der Adresse bestimmt das Netz, in dem sich der Zielrechner befindet. Der zweite Teil der Adresse identifiziert den Rechner innerhalb des Netzes. Die Länge der Netzadresse variiert in Abhängigkeit von der Größe des Netzes. Es gibt zwei Möglichkeiten die Länge der Netzadresse festzulegen. Früher wurden die IP-Adressen in Klassen unterteilt, die jeweils festgelegte Längen für die Netzadressen hatten. Dieses Verfahren wurde mittlerweile durch das CIDR (Classless Inter-Domain Routing) abgelöst. Hierbei wird die Länge der Netzadresse durch eine Netzmaske bestimmt. Diese gibt an, wie viele Bits der IP-Adresse das Rechnernetz identifizieren. Die Netzmaske ist ebenfalls ein 32-bit Wert, bei dem alle Bits, die das Netz identifizieren auf 1 gesetzt werden und alle Bits für die Hostadresse auf 0 gesetzt werden. Zum Beispiel hat ein Netz mit einer 16 Bit Netzadresse die Netzmaske 255.255.0.0. | |||||||
Soll ein Rechnernetz in das Internet integriert werden, so muss der Administrator einen Block von offiziellen IP-Adressen beantragen. Er erhält dann neben der zugewiesen Netzadresse auch eine Netzmaske. Die Adressen von Rechnern innerhalb eines Netzes können frei vergeben werden. Nur zwei Werte innerhalb eines jeden Netzes sind für spezielle Zwecke reserviert: | |||||||
| |||||||
Die Broadcastadresse wird verwendet, um alle Rechner innerhalb eines Netzes anzusprechen. | |||||||
Durch die Verwendung von Netzmasken ist es auch möglich ein Netz in weitere kleinere Teilnetze zu unterteilen, deren Verwaltung an andere übergeben werden kann. | |||||||
Die IP-Adresse 127.0.0.1 ist reserviert. Sie adressiert immer den eigenen Rechner. Dafür wird ein besonderes Interface (loopback device) verwendtet, welches alle ausgehenden Pakete wieder an den eigenen Rechner zurück liefert. Als Name für diese IP-Adresse wird localhost verwendet. | |||||||
Für Netze die keinen Anschluss an das Internet haben, wurden spezielle Blöcke von IP-Adressen reserviert, die beliebig verwendet werden können. | |||||||
ROUTING | |||||||
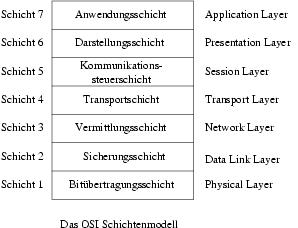
Doch wie findet ein Paket sein Ziel, wenn die Zieladresse bekannt ist? Da das Internet aus vielen einzelnen autonomen Netzen besteht, die alle miteinander verbunden sind, gibt es von einem Sender zu einem Zielrechner oft mehrere Wege. Das Internet besteht heute aus mehreren Millionen Rechnern. Diese zwei Tatsachen verdeutlichen, dass es unmöglich ist, dass jeder Rechner im Internet den Weg zu allen Rechnern kennt, mit denen er jemals kommunizieren möchte. Damit die Pakete dennoch ihren Weg zum Ziel finden, wurden an den Übergangspunkten zwischen den einzelnen Netzen Router eingerichtet. Router sind Rechner, die Pakete in Abhängigkeit von der Zieladresse in ein anderes Netz weiterleiten. Durch diese Weiterleitung kommt das Paket seinem Ziel Schritt für Schritt näher, bis es im Zielnetz angekommen ist und an den richtigen Rechner geliefert wird. Durch die Verwendung von Routern muss jeder Rechner im Internet nur noch wissen, an welche Netze er direkt angeschlossen ist und an welche Router er Pakete weiterleiten muss, damit sie richtig ans Ziel geleitet werden. In den meisten LANs bedeutet das, dass ein Rechner eine Route für die Rechner innerhalb des Netzes kennen muss und alle anderen Pakete an einen Router weiterleitet. Der Router analysiert das Paket auf der Vermittlungsschicht (siehe Abbildung) und entscheidet dann, an welchen Rechner das Paket im nächsten Schritt gesendet wird. Die Route die festlegt, an welchen Router die Pakete, für deren Zieladressen keine Eintrag vorhanden ist, weitergeleitet werden, heißt default route. | |||||||
Die Protokolle auf der Transportschicht definieren eine Ende-Ende-Verbindung. Dies bedeutet, dass alle Protokolle ab Schicht 4 aufwärts nichts von den Routern auf dem Weg der Pakete wissen, sondern direkt mit dem Zielrechner kommunizieren. | |||||||
ADRESSIERUNG DER ANWENDUNG AUF DEM ZIELRECHNER | |||||||
Wenn ein Paket auf Schicht 3 mittels des Internet Protokolls an den richtigen Rechner geleitet wurde, muss es noch auf Schicht 4 an die richtige Anwendung geliefert werden. Damit die Vermittlungsschicht auf dem Zielrechner entscheiden kann, welches Protokoll in der Transportschicht verwendet wird, enthält jedes IP-Paket die Protokollnummer des verwendeten Schicht 4 Protokolls. Die Protokollnummern können in der Datei /etc/protocols nachgelesen werden. In der Transportschicht werden die Anwendungen durch 16-bit Portnummern identifiziert. In jedem TCP und UDP Paket ist sowohl der Quell- als auch der Ziel-Port enthalten. | |||||||
Die Portnummern oft genutzter Dienste (die so genannten well-known ports) findet man in der Datei /etc/services. Zu beachten ist, dass Ports kleiner als 1024 auf UNIX Rechnern nur vom Benutzer root verwendet werden können. Darüber liegende Ports können von allen Benutzern verwendet werden. | |||||||
Die Kombination von einem Port und einer IP-Adresse nennt man Socket. Ein Socket identifiziert eine Anwendung eindeutig. | |||||||
| |||||||
Namensauflösung in IP-Netzen | |||||||
Die 32-bit IP-Adresse ist für Computer eine geeignete Möglichkeit um Rechner zu identifizieren. Für den Menschen jedoch sind Namen wesentlich einfacher zu merken als Zahlenkolonnen. Das Internet funktioniert vollkommen ohne Namen, aber es wäre wohl nie so erfolgreich geworden, gäbe es nicht die Möglichkeit, Rechner per Namen anzusprechen. | |||||||
Für die Konvertierung von Namen in IP-Adressen und umgekehrt gibt es zwei Verfahren: die Verwendung einer Host Tabelle und die Verwendung einer im Internet verteilten Datenbank, dem Domain Name Service (DNS). | |||||||
DIE HOST-TABELLE | |||||||
Die einfachste Möglichkeit zur Konvertierung zwischen IP-Adressen und Namen ist eine Tabelle, die alle Namen und IP-Adressen enthält. Unter UNIX findet sich diese Tabelle in der Datei /etc/hosts. Die Datei enthält in jeder Zeile eine IP-Adresse und den Namen (und alle Aliases) des Rechners. Die Verwendung der Host-Tabelle bringt jedoch einige Probleme mit sich. Die Methode skaliert sehr schlecht, und es ist nicht ohne weiteres möglich, die Tabelle automatisch zu verändern. Dies bedeutet, dass die Verwendung von Host-Tabellen zur Namensauflösung im Internet nicht sinnvoll ist, da hierfür jeder Rechner eine Tabelle mit allen im Internet erreichbaren Rechnern benötigen würde. Zudem müssten bei jeder Änderung alle Rechner im Internet die geänderte Tabelle beziehen und verwenden. | |||||||
Trotz dieser Probleme gibt es einige Fälle, in denen die Verwendung von Host-Tabellen sinnvoll ist: | |||||||
| |||||||
DOMAIN NAME SERVICE | |||||||
Im Internet hat sich schon seit einiger Zeit das Domain Name System durchgesetzt, da dieses die oben genannten Probleme von Host-Tabellen behebt: | |||||||
| |||||||
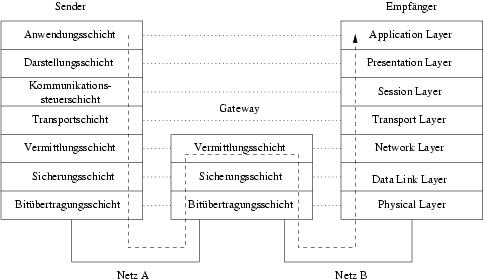
Der DNS Namensraum ist in hierarchische Domänen unterteilt und besitzt eine Suchbaumstruktur
(siehe Abbildung 1.3). Der Wurzelknoten dieses Suchbaums ist mit der Root-Domäne (".") beschriftet und die Kindknoten der Wurzel tragen als Beschriftung die Top-Level-Domänen (TLDs). Unter den TLDs verzweigen sich die Domänen weiter. | |||||||
| |||||||
Durch die hierarchische Untergliederung der Domänen in einen Baum ist keine zentrale Datenbank zur Abbildung von IP-Adressen und Hostnamen notwendig. Jeder Nameserver muss nur die Namen und Adressen der in seiner Domäne liegenden Rechner kennen, die Adressen der Nameserver der Subdomänen, sowie die Adressen der Root-Nameserver (um diese bei Bedarf fragen zu können). | |||||||
Die Root-Domäne im Internet wird von einer Gruppe von Nameservern gebildet, die nur Verweise auf die Nameserver der Top-Level-Domänen enthalten. Die TLD-Nameserver wiederum verweisen auf Nameserver eine Hierarchie-Stufe tiefer. Ein Nameserver, der für eine Domäne zuständig ist, liefert entweder die gefragte IP-Adresse oder verweist auf den zuständigen Nameserver der Subdomäne, in der sich der gesuchte Rechner befindet. | |||||||
Anwendungen richten ihre Anfragen immer an den DNS-Server im lokalen Netz. Kann der lokale Server die Anfrage nicht beantworten, fragt er solange die Hierarchie beginnend bei den Root-Nameservern ab, bis er eine Antwort (positiv oder negativ) bekommen hat und gibt diese an die Anwendung zurück. Damit das Netz nicht zusätzlich belastet wird, speichert der Nameserver Antworten in seinem Cache zwischen und gibt diese Antwort bei der nächsten Anfrage direkt zurück. Wie lange eine Antwort gespeichert bleibt, wird vom Administrator des Nameservers festgelegt. | |||||||
DNS-Server liefern jedoch noch wesentlich mehr Informationen über Rechner als nur den Namen oder die IP-Adresse. Die wichtigste Verwendung von DNS neben der Namensauflösung liegt in der Email-Konfiguration von Netzen. So können Einträge in DNS-Servern Informationen über zu verwendende Mailserver enthalten. | |||||||
Bei der Verwaltung einer Domäne ist es notwendig, mindestens zwei DNS-Server aufzubauen, damit die Auflösung von Namen der Domäne auch dann funktioniert, wenn ein DNS-Server ausfällt. Um den Aufwand für den Administrator zu reduzieren, und um zu verhindern, dass die zwei Nameserver unterschiedliche Informationen liefern, bietet DNS das Konzept von primären und sekundären Nameservern an. Der Administrator konfiguriert einen primären Nameserver, der immer auf aktuellem Stand gehalten wird. Außerdem kann der Administrator auf einem anderen Rechner mit relativ geringem Aufwand einen sekundären Nameserver aufbauen, der sich Änderungen an der Konfiguration automatisch vom primären Server holt. | |||||||
Hinweis Bei DNS wird häufig von Zonen gesprochen. Diese werden oft mit Subdomänen verwechselt. Der Unterschied ist zwar gering, dennoch von Bedeutung. Eine Zone ist der Bereich, für den ein DNS-Server verantwortlich ist. In den meisten Fällen entspricht die Zone somit einer Subdomäne, eine Zone kann jedoch auch mehrere Subdomänen enthalten. Dies ist der Fall, wenn nicht jede Subdomäne einen eigenen DNS-Server hat, sondern ein Server für die Namensauflösung mehrerer Subdomänen verantwortlich ist. | |||||||
Dynamische Konfiguration von Rechnernetzen | |||||||
Um einen Rechner in einem TCP/IP-Rechnernetz betreiben zu können, muss an ihm eine ganze Reihe von Einstellungen vorgenommen werden. So müssen IP-Adresse, Namensauflösung und Routen konfiguriert werden. Die dafür benötigten Informationen stehen aber nicht immer jedem Benutzer zur Verfügung. Um das Konfigurieren von Client-Rechnern (insbesondere von Rechnern die häufig in verschiedenen Netzen eingesetzt werden) zu vereinfachen, gibt es die Möglichkeit in Rechnernetzen spezielle Konfigurations-Server zu benutzen, die dem Rechner auf Anfrage alle benötigten Informationen zur Verfügung stellen. Ein Protokoll, das für diesen Zweck entwickelt wurde, ist das Dynamic Host Configuration Protocol (DHCP), eine Erweiterung des Bootstrap Protokolls (BOOTP). | |||||||
Soll ein Rechner seine Netzkonfiguration von einem DHCP-Server beziehen, so sendet er einen DHCPDISCOVER-Paket in das Netz. Da der Rechner zu diesem Zeitpunkt noch keinerlei Information über das Rechnernetz hat, ist dieser Request nicht direkt an den DHCP-Server gerichtet, sondern wird vielmehr als Broadcast gesendet. | |||||||
Der DHCP-Server liest alle Pakete im Netz mit und antwortet dem Rechner mit einem DHCPOFFER-Paket, das alle erforderlichen Konfigurationsdaten enthält. Der Rechner sendet darauf ein DHCPREQUEST-Paket und kann nach Bestätigung durch ein DHCPACK-Paket des Servers seine Konfiguration mit den erhaltenen Daten vornehmen. | |||||||
DHCP liefert dem Client nicht nur alle notwendigen Parameter zur Konfiguration des Rechners, sondern ermöglicht die dynamische Vergabe von IP-Adressen. Dabei werden den Clients die IP-Adressen für eine bestimmte Zeit zur Verfügung gestellt. Benötigt der Rechner die Adresse länger, muss er beim DHCP-Server eine Verlängerung beantragen. Wird die Adresse nicht verlängert, vergibt der DHCP-Server die Adresse bei Bedarf an einen anderen Rechner. Die dynamische Verwendung der IP-Adressen ist sinnvoll, wenn in einem Rechnernetz häufig Rechner hinzukommen oder entfernt werden. Es ist nicht sinnvoll, Servern jeglicher Art dynamische Adressen zuzuweisen, da Server im allgemeinen immer unter derselben Adresse erreichbar sein sollten. Es ist aber durchaus möglich alle Rechner in einem Rechnernetz, bis auf den DHCP-Server selbst, per DHCP zu konfigurieren. | |||||||
Theoretische Aufgaben | |||||||
1. ADRESSIERUNG IM INTERNET | |||||||
Erkären Sie kurz das Verfahren der Unterteilung der IP-Adressen in Klassen. Welche Probleme / Nachteile wurden durch die Einführung von CIDR behoben? | |||||||
2. WEGEWAHL PROTOKOLLE | |||||||
Nennen Sie die wichtigsten Protokolle der Internet-Protokoll-Familie zur dynamischen Wegewahl und erläutern Sie kurz die wichtigsten Eigenschaften der Protokolle. | |||||||
3. NAMENSAUFLÖSUNG | |||||||
| |||||||
4. DYNAMISCHE ADRESSVERGABE | |||||||
Welche Nachteile ergeben sich durch die Verwendung von dynamischen Adressen in einem Rechnernetz? Welche Möglichkeit gibt es, diese Nachteile zu umgehen? | |||||||
| ||||||||||